Activation Functions¶
Neural networks rely on a nonlinear transformation to learn nonlinear relationships in data. These nonlinear transformations are typically fixed functions that are applied after a linear transformation of the data. The linear transformation uses learned weights, while the nonlinear function is fixed in that there are no learned parameters. In most cases, these nonlinear functions can be thought of as activation functions that indicate the state of a unit within a layer of a neural network, given some data.
-
class
slugnet.activation.ReLU[source]¶ Bases:
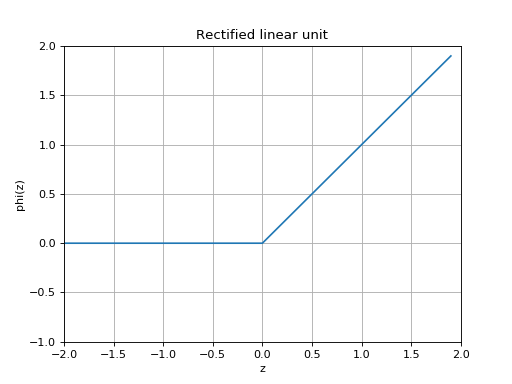
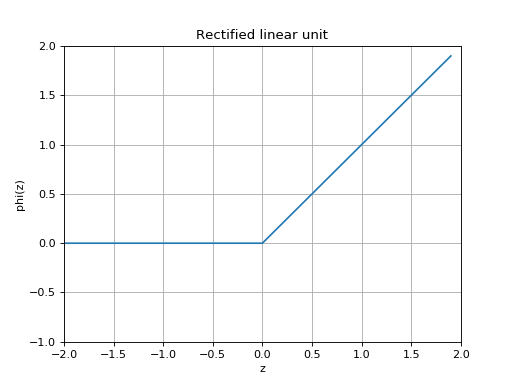
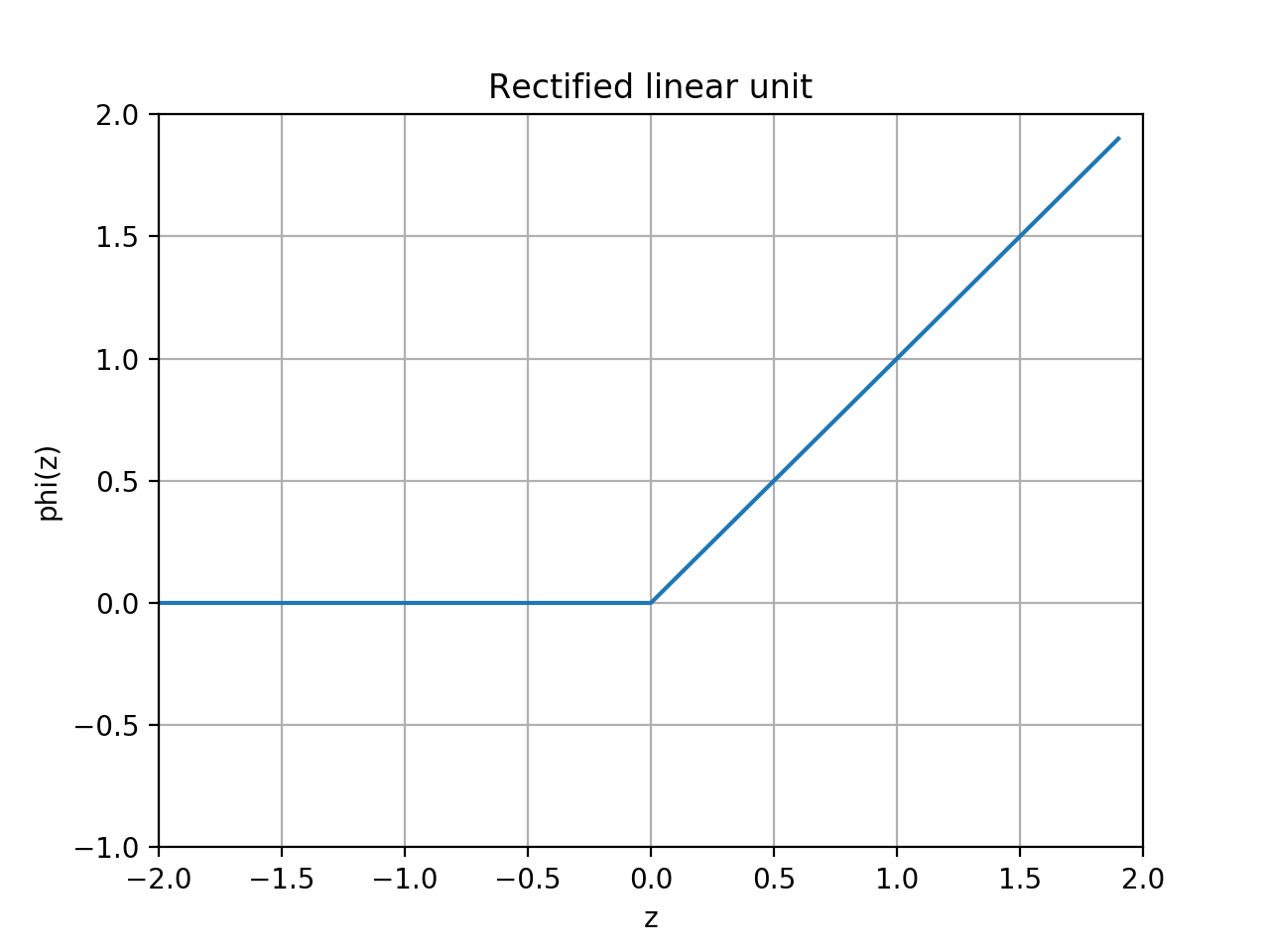
slugnet.activation.ActivationThe common rectified linean unit, or ReLU activation funtion.
A rectified linear unit implements the nonlinear function
 .
.(Source code, png, hires.png, pdf)
-
class
slugnet.activation.Tanh[source]¶ Bases:
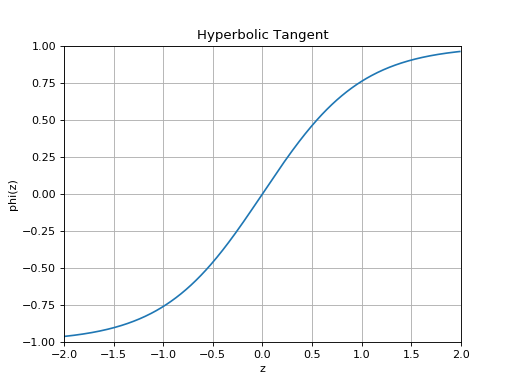
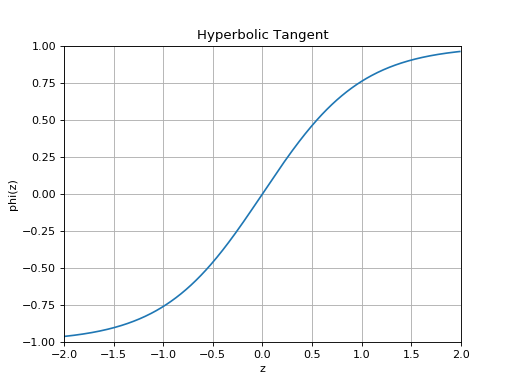
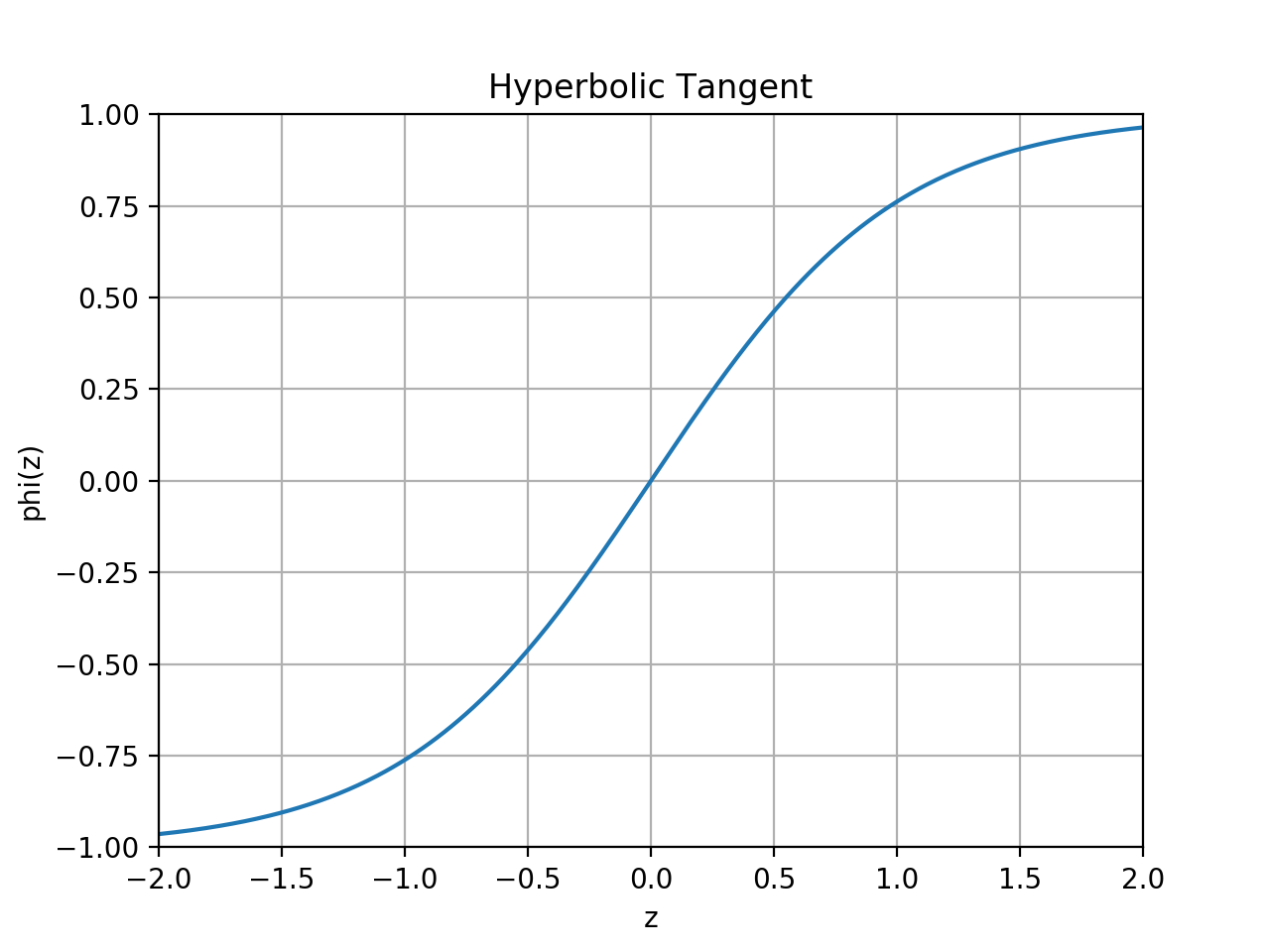
slugnet.activation.ActivationThe hyperbolic tangent activation function.
A hyperbolic tangent activation function implements the nonlinearity given by
 , which is
equivalent to
, which is
equivalent to  .
.(Source code, png, hires.png, pdf)
-
class
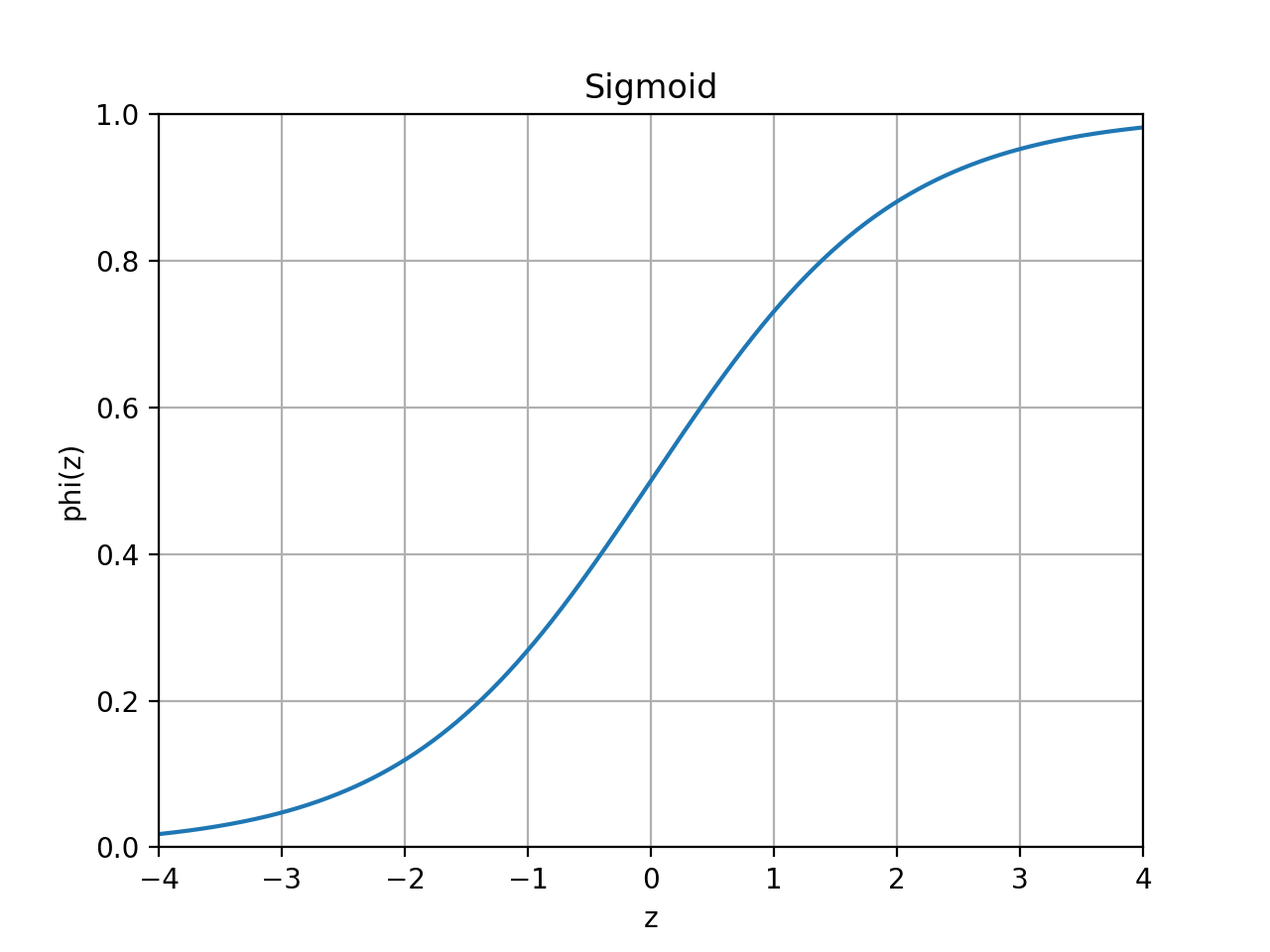
slugnet.activation.Sigmoid[source]¶ Bases:
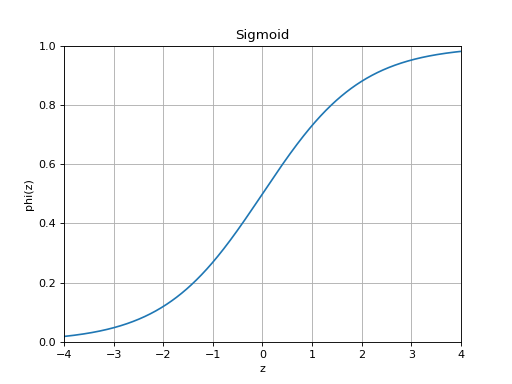
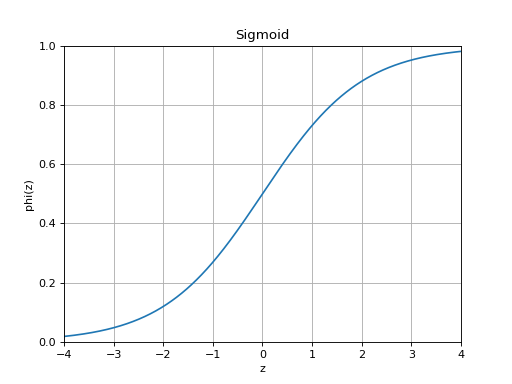
slugnet.activation.ActivationRepresent a probability distribution over two classes.
The sigmoid function is given by
 .
.(Source code, png, hires.png, pdf)
-
class
slugnet.activation.Softmax[source]¶ Bases:
slugnet.activation.ActivationRepresent a probability distribution over
 classes.
classes.The softmax activation function is given by

where
 is the number of classes. We can see that softmax is
a generalization of the sigmoid function to classes. Below,
we derive the sigmoid function using softmax with two classes.
is the number of classes. We can see that softmax is
a generalization of the sigmoid function to classes. Below,
we derive the sigmoid function using softmax with two classes.
We substitute
 because we only need one variable to
represent the probability distribution over two classes. This leaves
us with the definition of the sigmoid function.
because we only need one variable to
represent the probability distribution over two classes. This leaves
us with the definition of the sigmoid function.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}